
FORENSIC SPEAKER IDENTIFICATION
FORENSIA: Automatic system of forensic identification of speakers

The FORENSIA 2.0 automatic speaker identification engine is developed with the latest technology based on standardized total factor vector (i-vectors) and channel compensation (PLDA) approximations. The system compares the evidence to up to five voice planes. The result obtained indicates the proximity of the pairs of voices compared, which are evaluated in relation to a universal database using the Bayesian inference method (LLR) -the same that uses DNA comparison. This system was part of the Speakers in the Wild (SITW) evaluation developed by SRI International during 2016 and was verified with data from the 2012 NIST HASR evaluation. To access a system DEMONSTRATION , being able to enter your own audio files, request a password by email.
EVAPEFOR: Perceptual Forensic Identification System
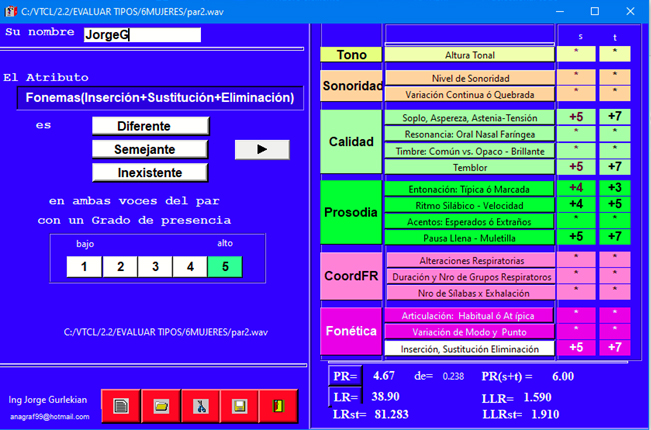
This program allows the discrimination of two voices based on the most relevant perceptual attributes. From the score obtained, the system automatically presents the value of LR and LLR. In this way, the results of the human evaluation can be merged with those of the automatic system, becoming the ideal complement to present in the expert report. The system normalizes the typicality aspects of the attribute to be evaluated since a voice can also be very similar to that of other speakers in the reference population. The typicality measure is obtained by listener responses to pairs coming from different speakers and by assigning extra points to the similarity scores for each relevant voice attribute present in the two voices to be compared.
VOX: Formant-Based Speaker Identification System
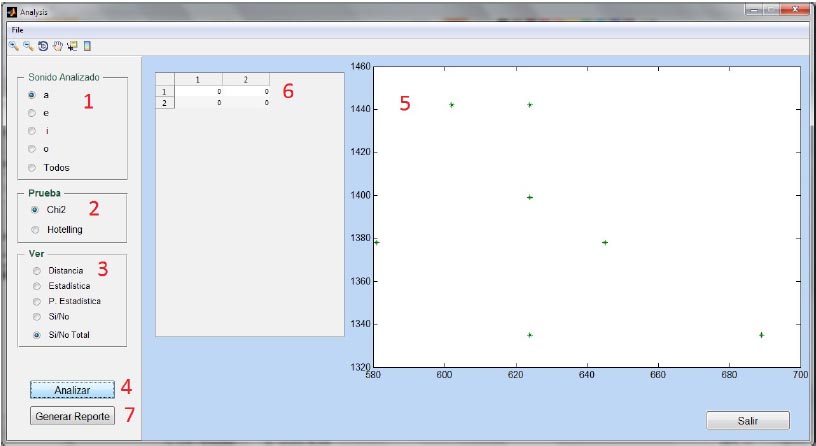
The system is made up of a statistical analysis module that allows performing the specific tasks necessary to solve the problem of identifying speakers based on measurements of formant values and fundamental frequency (F0) of the vowels / a /, / e / , / i / and / o / (the / u / is not considered to be rare in Spanish from Argentina). Using VOX analysis, it is possible to determine the likelihood that two formant data sets and F0 correspond to the same speaker and additionally the likelihood ratio (LR). For this, the inter-speaker and intra-speaker variability is modeled using covariance matrices of the variables under study according to Hotelling’s χ² or T² tests. See more…
SEGMENT: Audio File Segmenter
This tool allows you to select a specific input file and obtain fragments of it in segmented audio files. It detects regions of silence that are suitable for segmentation, and considers a threshold of minimum and maximum durations for each fragment. See more…
FILTER: Acoustic filtering
Audio signal conditioning stage that reduces the noise present. It allows applying low-pass, high-pass, band-pass or band-reject filters, as well as the possibility of using two different filtering families: Chebyshev or Sinc. See more …
LEXICON: Lexical Label Editor
Simple and agile application for lexical transcription of the content of an audio file. See more …
________________________________________
VOICE ANALYSIS
ANAGRAF: Acoustic Analysis and Speech Sign Graphing
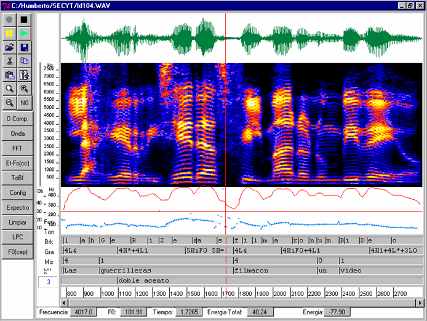
Some System Features: Waveform, Narrow / Wide Band Spectrogram, LPC, Row Peaks, LTAS, Zero Crossings, Energies, Fundamental Frequency (Shimmer, Jitter, H / N, Lyapunov Coefficient), ToBI Transcript, SAMPA Alphabets e IPA, vocal risk assessment, integrated disturbance index (IPI), vocal precision index (IPV), energy utilization index (IAE), phase portraits, speech synthesis, glottal wave, phonoaudiological reports. See more …
EVAPER: Perceptual Evaluation System
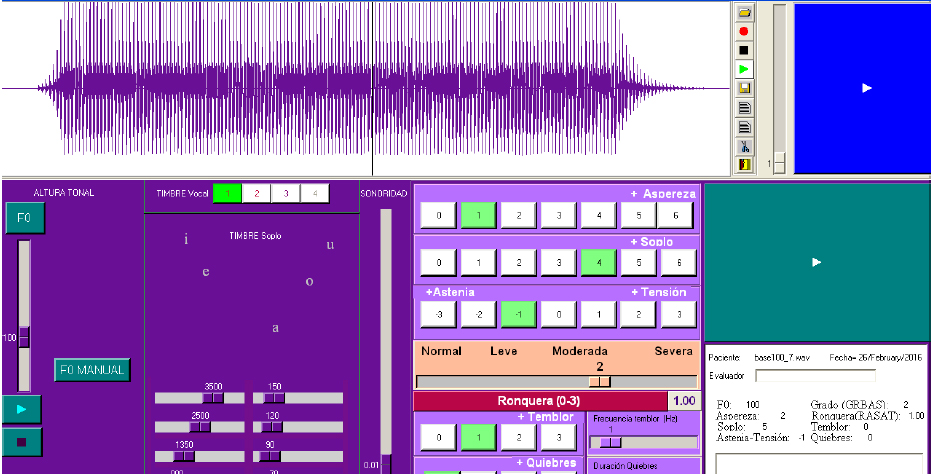
This tool is based on the psycho-acoustic method of magnitude production and intramodal contrast. It allows the perceptual evaluation of the roughness of a patient’s voice when the deviations of the responses obtained with the classical method of numerical estimations are compared. The patient’s voice is evaluated sequentially by selecting the following parameters: pitch (pitch), loudness (loudness), timbre (formant structure), roughness / hoarseness (roughness), noise or air leak or breathiness (breathiness), asthenia or tension (asthenia-strain), tremor or instability (tremor) and number of breaks (breaks). See more …
ATR: Real Time Speech Analysis and Phonetogram
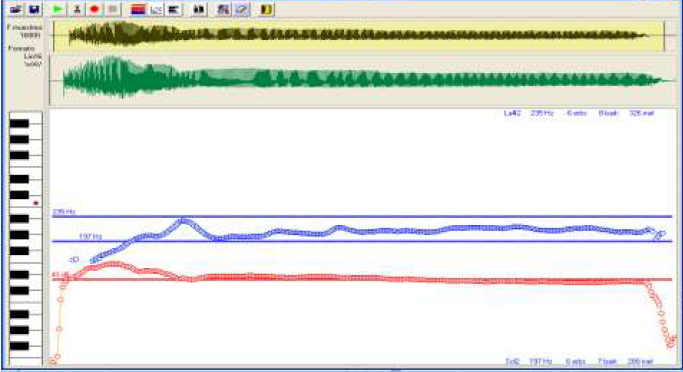
The phonetogram is a tool used for the analysis and rehabilitation of the voice at a clinical level that allows graphically visualizing and objectively evaluating the state of the parameters that make up a person’s vocal range. Among its possible applications we find the vocal training of singers, the evaluation of voices currently used in the educational environment, among others. See more….
